Improving AI Performance with Reactive Agents
The Exponential Problem
Have you ever encountered quality or performance issues with a feature in an app or project you were working on? How did that go? If you are like me, you're familiar with the struggles and headaches that come with improving advanced AI features. If you haven't run into this problem yet, then let me show you before you run into what I call "The Pipeline Problem."
Let's use a Banky as an example: an assistant that you have been tasked with implementing at the bank where you work. The marketing team is ready to send the following announcement to all users of the app:
"Introducing Banky, the AI assistant that you can chat with, ask about transactions, and manage your account. Banky can help you find purchases you have made and tell you were you are spending the most."
You have already invested significant effort and time in building Banky and have applied best practices to ensure it works as expected. You are already using one of the latest and most expensive LLM models. You are already using a multi-node setup to handle different parts of the agent:
- The
transactionsnode is in charge of fetching transactions, examining them, and formatting them in a way that other nodes can easily understand. - The
accountnode is responsible for viewing and modifying account settings. - The
spendingnode is responsible for presenting and visualizing transactions in a manner that is easy for humans to understand. - The
generalnode is responsible for other chatting experiences. - Etc.
However, you have been getting complaints from testers that asking about transactions is not working well, and that the assistant often hallucinates new transactions. When you start investigating, you can reproduce the problem, but only about 1 in 20 times (using the transaction data in your test account). However, since this is a multi-node setup, you don't know which node is causing the issue.
After a few hours of debugging, you find that the spending node is receiving the correct transaction data from the transactions node, but specific patterns of data will cause it to hallucinate. Meaning that other users may be seeing hallucinations much more often than you are. You try to improve the model's performance by doing any of the following:
- Improving the prompt:
- Being more descriptive about the expected output.
- Breaking down role, action, goal, etc.
- Give more examples of the output.
- Adjusting hyperparameter values:
- Lowering the temperature value so its output is less creative.
- Increasing the reasoning effort, so that it can try to catch its own mistakes.
You change all of the above several times until you get a configuration that works well for you, and now you only encounter hallucinations 1 out of 100 times in your account. The entire process of changing the configuration and re-testing conversations took over a week. You push the updates and get ready for a vacation. That is, until you get new feedback from testers saying that hallucinations got worse since the last update. You knew this could happen, since you only used the data in your account to test the new changes.
What do you do next? Will you ask for every single conversation testers are having and manually ensure that no hallucinations occur? Do you instead build and ship a performance suite within the app to track the response quality?
Now you have reached what I like to call "the exponential problem." For every performance bit you want to increment, you have to spend exponential time, exponential effort, exponential resources, and even grow exponential gray hairs. All this manual work for a bit of sub-optimal performance.
What is a Reactive Agent?
We have been working to improve the AI space for everyone over the past few months, exploring different ways to tackle the pipeline problem, and we have developed a new type of AI agent. We refer to this new agent as a Reactive Agent, one that not only reacts to human input to create an output, but also reacts to its own performance to change itself. A true reactive agent in all senses, meaning it can change its own system prompts, hyperparameters, and even AI models in real-time, without requiring developer intervention or code changes.
You can see the full draft specification for reactive agents here: https://github.com/idkhub-com/reactive-agents/blob/main/specifications/v0_1_0.md
The Pros:
- Reactive agents are easier to set up than regular agents. One or two sentences describing each node is sufficient to set up an agent. Each node within an agent uses the description to set up its initial performance evaluations and system prompts.
- Reactive agents are provider-agnostic by default. Each node within an agent can switch between models in real time, depending on each model's response quality. We recommend using models across multiple providers, such as OpenAI, Anthropic, and Ollama, to automatically find the most optimal model for the job.
- Reactive agents continually improve their own performance without external intervention. Each agent continuously evaluates its own performance and selects the most efficient configuration based on an algorithm (defined by the implementation).
- Reactive agents can reach higher performance than regular agents by design. A central aspect of the reactive agent implementation is that each node within an agent has built-in support for request partitioning. Each partition has its own configuration that optimizes performance for a subset of requests sent to a node. A node can automatically route requests based on various characteristics, such as semantic meaning, input token length, etc. (depending on the implementation). For example, it could turn out that a node sends 70% of the requests to Claude Sonnet 4.5, 20% to GPT 5.1, and 10% to a custom model.
- Reactive agents have built-in observability. Since each agent needs to see how it is performing in real time, it inherently uses observability. This observability is automatically available to the developer, including input and output, as well as scores for the evaluation metrics enabled for the agent.
- Reactive agents cost the same or less in the long run compared to regular agents. Reactive agents cost less because it is far more likely you will find an optimal configuration for an agent by letting it self-optimize itself than by manually optimizing it. Self-optimization often means finding cheaper models that perform as well or better than your current setup.
The Cons:
- Reactive agents can feel more high-level than regular agents. The more control you give to the reactive agent, the more autonomous it becomes, and the less you will want to customize it. You can still control all aspects of an agent, such as system prompts and hyperparameters, but it can feel like going against the reactive agent's nature.
- Reactive agents can cost more initially. While finding the optimal configuration, each agent uses more tokens as it is continuously evaluating its own performance. Once you are satisfied with a configuration, you can, of course, pause the self-optimization, and the cost will be the same or less than that of a regular agent.
- Reactive agents can take a high number of requests to find the optimal configuration. The time it takes to find the optimal configuration for an agent depends on its complexity, the number of models your agent is allowed to use, the number of partitions you set for each node, the level of risk you are willing to take, and many other factors. This time will also be heavily affected by the algorithm used by the reactive agent implementation you use. Generally speaking, it can take dozens of requests to find a decent configuration and hundreds to thousands to find an optimal one.
The Reactive Agents Project
This week, we released the first version of the Reactive Agents project, the first implementation of the reactive agent technology, and made it open source under the Apache 2.0 license. Please note that this is an alpha release and is not yet production-ready. We are working to make this implementation production-ready in the coming months.
You can find the repo here: https://github.com/idkhub-com/reactive-agents
The Reactive Agents project consists of the following components:
- A server that operates all the reactive agents.
- Routing of requests from your application (via the OpenAI API), and fulfills them.
- Support for multiple-providers including (OpenAI, Anthropic, Google, xAI), with many more coming soon.
- Support for agents with different capabilities (skills/nodes).
- Background self optimization of agents.
- Various evaluation methods to assess the agent's performance.
- A user interface to easily deploy, manage, and observe the status of each agent and the state of their algorithm.
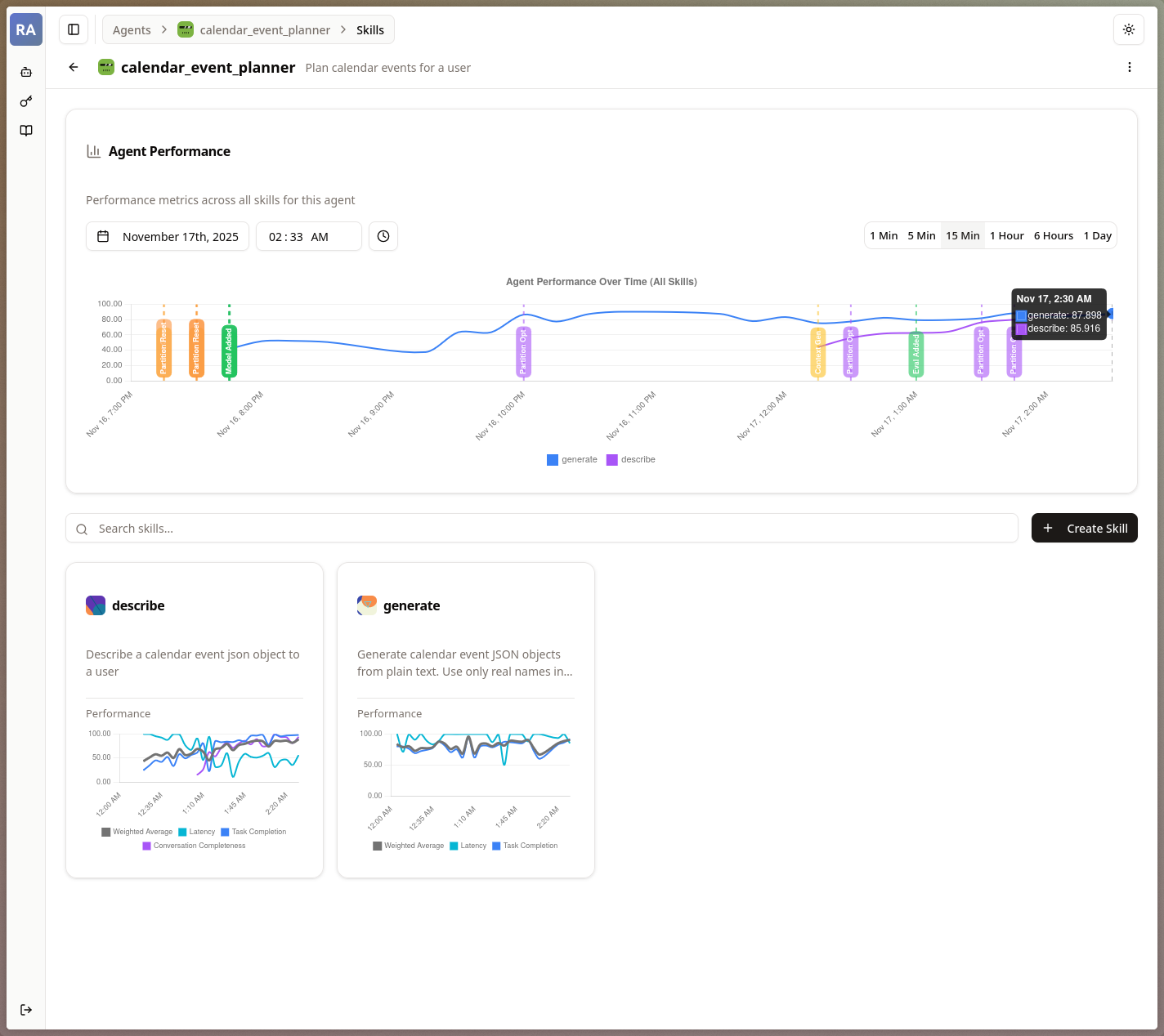
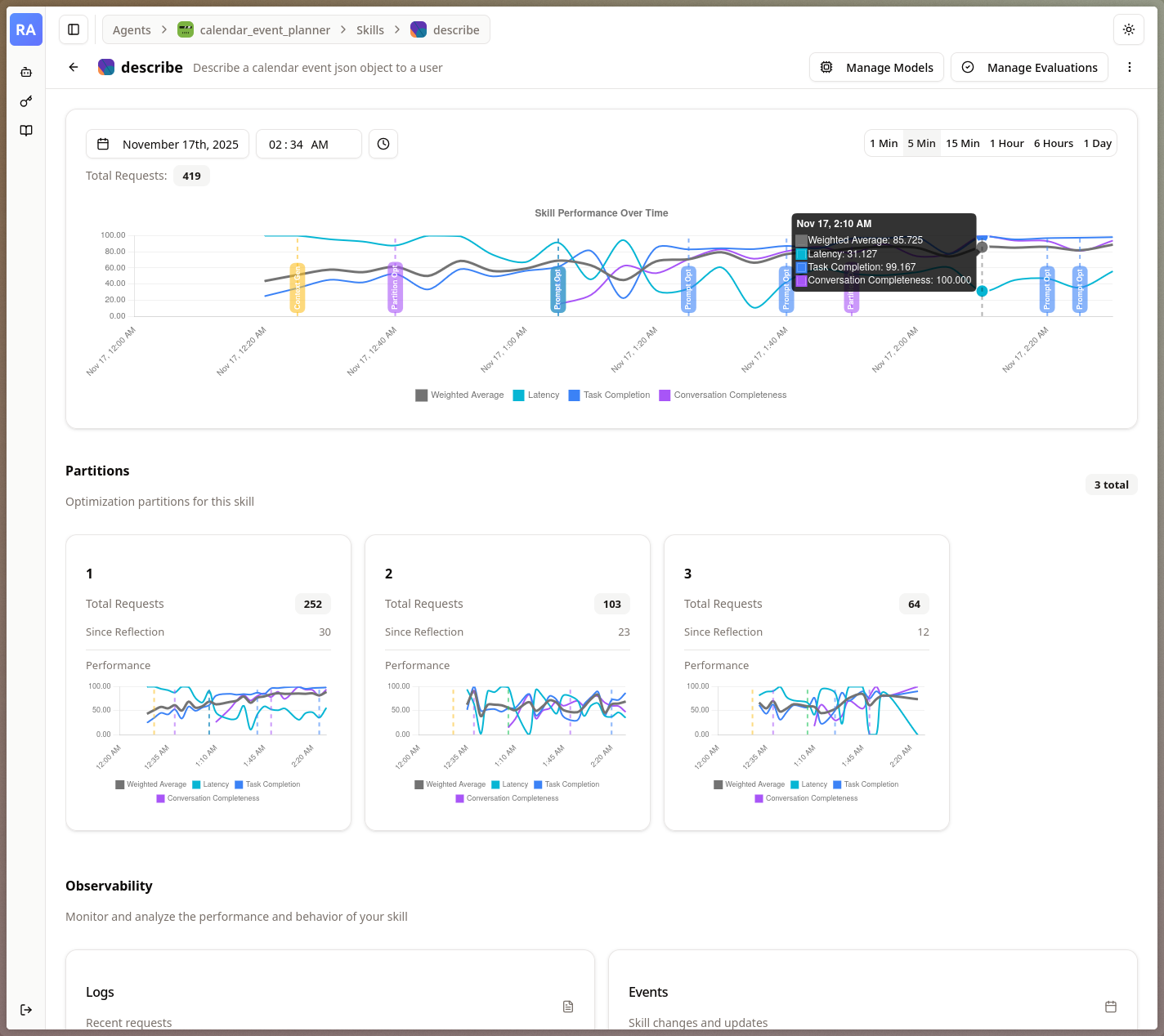
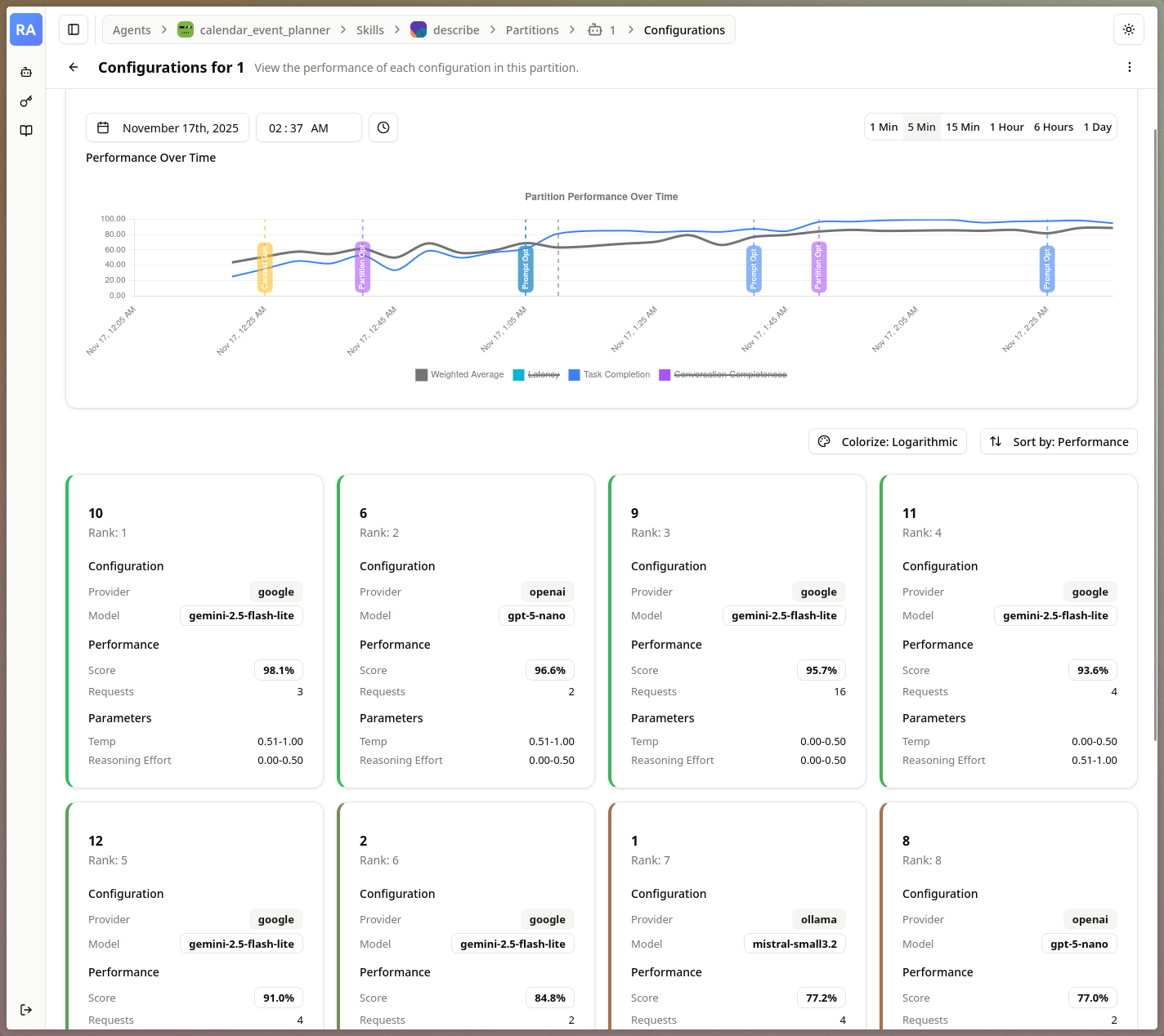
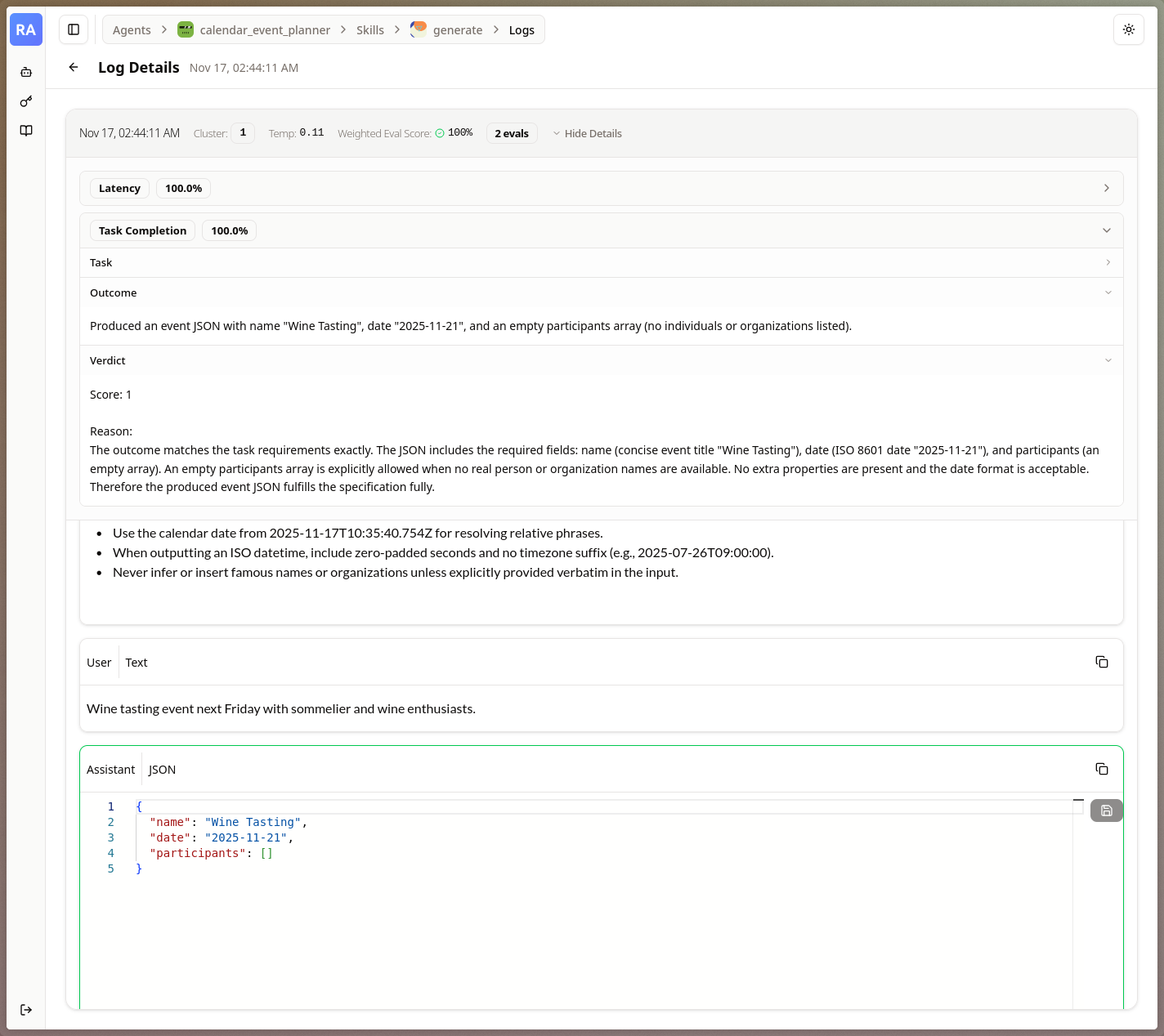
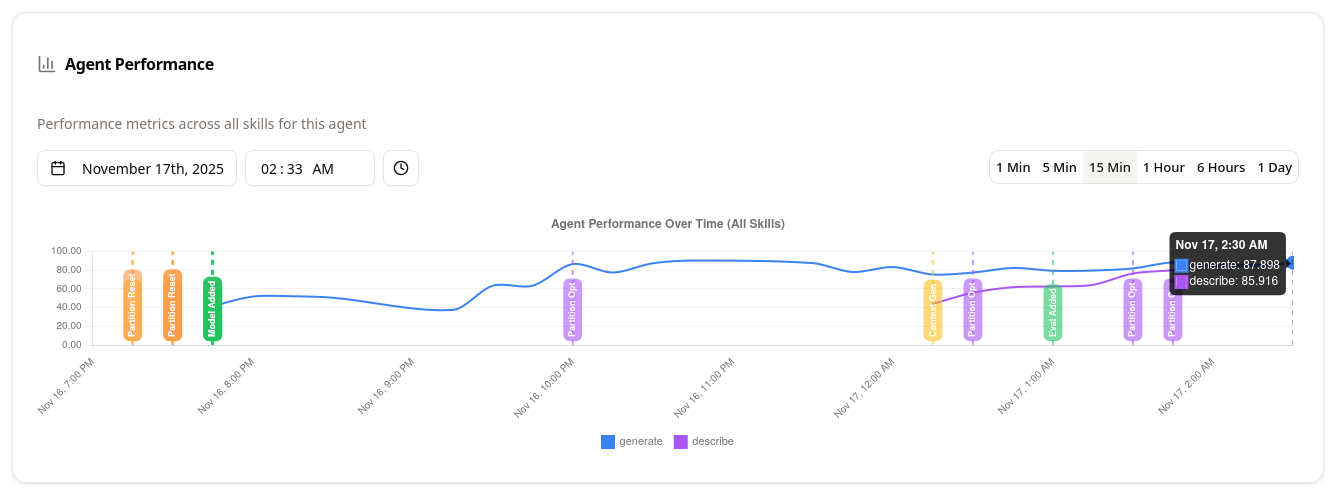
The gallery shows different views within the Reactive Agents Project, including performance, algorithm state, and the built-in request observability.